

The first of two posts talking about some software I wrote to solve a need, which does in fact do its job really well, but because I'm following the IDGAF approach to the development process - the thing is a trainwreck under the hood and you could say I totally get why windows is closed source. This first part talks about why I needed to make the software, walks through the user-interface and other such surface level things. In the next article I will cover more specifically what clear examples of technical debt are shining brightest and how they can be paid off properly.
What are you talking about?
In this post I'm going to give a tour of a personal software development project that is an ongoing monstrosity of bad implementation, poor design choices and so on... and yet... it works, fulfils the need it was built to fill and somehow sparks joy for me on so many levels.
Why should anyone care about this?
Well, if you're interested in software development, you'll learn a bit about software design principles but also something quite difficult to wrap the neophyte mind around: the idea of "technical debt".
The focus of this post is what I'd call a classical example of the technical debt most software-dependent companies have to deal with in one way or another. We're not going to look at the technical debt right away, and instead we're going to get to know the software itself, why I made it and so on. This is important in order to understand the second part of this two-part posting.
So what is "Technical Debt"?
Technical debt is a term used to describe a subtle problem in the software development lifecycle that arises over time based on the micro-choices developers make when implementing changes to the codebase.
Wikipedia's definition:
Technical debt (also known as design debt or code debt, but can be also related to other technical endeavors) is a concept in software development that reflects the implied cost of additional rework caused by choosing an easy (limited) solution now instead of using a better approach that would take longer.
https://en.wikipedia.org/wiki/Technical_debt
Let's talk about "The Necessity"
It is very common for the hacker-minded to "whip up" or "MacGuyver" a fix for the problem at hand and based solely upon their deductive reasoning and creativity. This is in fact at the heart of a sort of principle I've identified in life and by which I follow, it goes something like this: "don't invent systems, reveal them with the language to fully define the necessity driving the creation".
Okay, so what was the necessary reason for me to create this monstrosity of a software project? Very simple, I suck as a DJ. For example, my taste in music to mix is so wide and genre-busting that invariably the tracks are virtually unmixable for me. The intro of the next is completely counter to the extro of the previous. The double-tap of the breakbeat just does not line up with the trap drops or trance melodies.
Alright, so I'm not very good at this DJ thing in terms of raw talent. This is fully true. I've started this path of self-development from a place of nearly zero talent and rhythmic skill. I know how to play a guitar and just enough of the piano to know what middle C is and that's the extent of my musical talent. Everything else I can do is entirely self-taught, in virtually every facet of my life.
This rut I was in when I first got my hardware, it was a silent sucker punch and I wasn't going to let this "technicality" stop my DJ fantasy from becoming the reality I desired.
This rut evidenced the need to have some means of generating a setlist I could rely upon to feed me a stream of track names that would make the job of mixing them together dramatically easier.
But why is my desire to DJ my own sets so important that I should invent solutions to the perceived problems and barriers? I love music. Music is a fundamental aspect of being and I use music (and it's counterbalance, silence) to manipulate my mental, emotional and physical states with some precision.
I can, with a good set flowing through the speakers, hit a software development mindset where the friction of work is minimized, my mind pours over the language and symbols encoding human intent into machine action, and like this paragraph, the code just flows on and on, somehow hitting the mark and making the point clear and useful.
The sufficient reason for my need to be a DJ is so that I can manipulate my states of mind with effective and predictable results.
The sufficient reason for my need to create this software project is so that I can reduce the friction of actually mixing my own sets, because when I can integrate deeper emotional connections to the music, then the impact within my stateful changes are even more resonant and resounding.
Some history
Around late 2014, early 2015, I'd acquired some used turntables and a basic 2-channel mixer. Nothing fancy at all and yet exactly what I was looking for and the seller (a personally highly regarded individual) was thrilled to be letting their babies go to a new home that'll give them some love and give them purpose again beyond consuming closet space.
You can read up a little about the gear I use: Practice Decks.
(Shout-out to Bigby, you know who you are. Miss you bud.)
Percolating some genius
After having decided that software was going to help solve my organic-brain problem of building setlists, one would think I just sat down and started writing some muckery code and the thing is off to the races. Sorry, but this isn't how I function exactly. For the first few days I did literally nothing but think about the intro minutes and extro minutes of any given pair of tracks. This "thinking" though is a predominantly silent process. Very few actual "sentences" flow through my mind and instead while I'm actively doing other things, including sleeping, these bubbles of idea-sensations float up from the void and into conscious mind space. They include feelings, sounds (not necessarily words), sensations, emotions and visions - all for the purpose of rendering what the parts of me that don't understand English but have electrochemical thoughtforms to contribute... what some would call "flashes of insight" or whatever, I've refined into an active skill. Anyways, that's a topic for a different project that's forming on my sidelines.
So, what's the genius that percolated here?
Simple abuses of the mathematical nature of digital audio. It's so silly and stupid. Any sound engineer in their right mind would chop this down and replace it with something better, but the problem here is that I don't know the something better, I'm not a sound engineer.
Here's what the Proof-of-Concept code I wrote basically did:
-
Importing tracks:
- Given a list of MP3 file paths on STDIN
-
For each MP3 file:
-
derive two magic (floating-point) values: intro and extro
- use SOX to capture the first and last minutes as raw sample data
- simply add up the numeric value of each and every sample in the raw data and then divide it by the total number of samples in the segment (intro and extro segments are independently derived)
- store the track metadata and magic values in a CSV (ad-hoc DB)
-
derive two magic (floating-point) values: intro and extro
-
Generating setlists (given max number of tracks for this list):
- load the current CSV metadata snapshot
- randomly select a starting track
-
begin looping until number of selected tracks hits the cap
- take the previous track's extro value
-
loop until rejected threshold hit (hard coded value)
- randomly select another track (that isn't already selected)
- if it's intro value is not within hard-coded threshold, reject, else select
- take all selected tracks and output a new CSV to STDOUT
All of this was written in Perl, used some modules for parsing of MP3 data and so on. No, none of this code should see the light of public display. It's all horridly bolted upon layers of more technical debt... because of course I didn't just stop there.
The ideas that had percolated not only included these raw-sample-magic-values but also included lots of other fantastically useful features like making each new track pick in the tight loop to also follow key progressions (standard key notation, not the Camelot form) and so on.
Overall, while the Proof-of-Concept "did the job", it was abysmal to expand upon, data storage was questionable at best, required arcane invocation sequences to run and, well, didn't meet the long-term need. However, in proving that I could now generate setlists that actually made sense, followed keys and generall took the pointy end of the DJ stick away from the picture.
I now wanted more because this little bit of "done" revealed a maze of ideas and aspirations that the engine of more had been kickstarted at full throttle.
Solving the need, the birth of "OSDJS"
OSDJS stands for "One State DJ Studio", the name for the umpteenth iteration of the original Perl scripting work. The following points amounted to the initial "spec's 'n 'reqs" mandate I'd set for the new project.
- MUST provide a GUI, curses acceptable, Gtk desired
- MUST have a command-line interface
- MUST integrate usage of SOX, bpm-tools and keyfinder-cli
- MUST use a real DB, sqlite preferred, don't use full servers
- MUST act like a well behaved software (menus, cosmetics)
- MUST use a "builder model" for playlist generation
- MUST store all playlists generated
- MUST allow for exporting playlists in M3U format
- MUST allow for playing the tracks individually
- NICE to have list was so long it was easier to focus on MUSTs
The language
I love learning new programming languages when the need arises and in this case I had been seeking a project that didn't matter to anyone but would be useful to me, didn't have any deadlines and was needing a GUI.
After much research and flip-floppery, I selected Go for the language. Some of the other languages I'd considered:
- Perl: I love Perl, I think in Perl, regex games are a yummy breakfast and there is no reason I shouldn't have stuck with just Perl other than I wouldn't be learning a new language. I'd have gotten the project done at least 50% faster and it'd be much more flexible, however, this thought did not spark any joy
-
Rust: language looks cool, ecosystem maturity lacking, support/learning community let me down or otherwise made it impossible to learn so many times that I have put Rust on a permanent backburner
- Note: I do believe it will mature and be a titan of computing someday, just not today
- Java: libraries for audio manip kept popping up in search results, lacked the esthetics I was looking for and no I don't want to run tomcat to do that thing with the beans and frameworks and so on just to organize my data
- JS: I don't know what I even considered this path, I wouldn't have been learning a new language and I'm not even going to discuss this further lol
The codebase
For the GUI, I went with Go-Gtk. I don't know this mattn person beyond their Go code, but I would like to extend a very warm and sincerely appreciative Thank You to them for all their contributions to Go and open source in general.
Here's a brief list of other libraries involved:
- alecthomas/kingpin
- faiface/mainthread
- hajimehoshi/go-mp3
- krig/go-sox
- mattn/go-sqlite3
- wtolson/go-taglib
Moving along, having researched enough, having percolated enough ideas and emotional momentum, I sat down and hammered out a codebase.
Using scc, here's the default report (includes vendor and more):
$ scc osdjs/
Language Files Lines Blanks Comments Code Complexity
-------------------------------------------------------------------------------
Go 510 113977 12832 14256 86889 14270
C++ 37 4098 513 1009 2576 306
Markdown 34 3029 821 0 2208 0
C Header 31 15114 683 9818 4613 160
License 21 1949 330 0 1619 0
Makefile 14 498 98 84 316 34
Shell 8 345 35 50 260 19
Plain Text 5 462 131 0 331 0
C 4 210316 6062 28559 175695 7624
Go Template 4 10 0 0 10 0
Perl 4 531 28 10 493 12
YAML 3 53 9 4 40 0
gitignore 3 17 0 0 17 0
Assembly 2 1220 64 0 1156 18
JSON 2 26 0 0 26 0
Prolog 2 186 24 0 162 2
Protocol Buffers 2 635 85 94 456 0
TOML 2 72 7 50 15 0
C++ Header 1 11339 1833 493 9013 1056
Patch 1 13 2 0 11 0
-------------------------------------------------------------------------------
Total 690 363890 23557 54427 285906 23501
-------------------------------------------------------------------------------
Estimated Cost to Develop $10,247,779
Estimated Schedule Effort 37.147542 months
Estimated People Required 32.677914
-------------------------------------------------------------------------------
Here's just the actual source code I wrote:
$ scc osdjs/src
-------------------------------------------------------------------------------
Language Files Lines Blanks Comments Code Complexity
-------------------------------------------------------------------------------
Go 54 9953 689 735 8529 1356
-------------------------------------------------------------------------------
Total 54 9953 689 735 8529 1356
-------------------------------------------------------------------------------
Estimated Cost to Develop $256,471
Estimated Schedule Effort 9.147983 months
Estimated People Required 3.320991
-------------------------------------------------------------------------------
I find these statistics very interesting because they do in fact give a fair ballpark figure for the time and effort invested. While I have been working on this codebase since early 2018, I really don't put a lot of effort into it anymore. It just does what I need it to do and every now and then something new pops up on the tech radar and demands itself be integrated into OSDJS... such as Deezer's spleeter, but we'll talk about that later in the "technical deb" postmortem I'm building up to in this post.
Let's see it already!
Okay! Here you go!
$ ./bin/osdjs help
usage: osdjs [<flags>] <command> [<args> ...]
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
-L, --language=LANGUAGE Set the language to use
-v, --verbose Output verbose logging
-q, --quiet Silence all output
-D, --database=DATABASE Path to the application db
Commands:
help [<command>...]
Show help.
import [<flags>] <file>
Add music to the library
play <track>
Play a given track by ID
version
Print the application version
export [<flags>] <playlist> [<file>]
Export music in the library
list [<flags>] [<playlist>]
List music in the library
shell
Start an interactive shell
gui [<flags>]
Start a gui session
Okay, so that's what the command line help docs look like. Nothing fancy, just
the normal unix-y goodness I love so much. What about this Gtk GUI thing? What's
it look like? Well... let's take a look at some screenshots of that gui command.
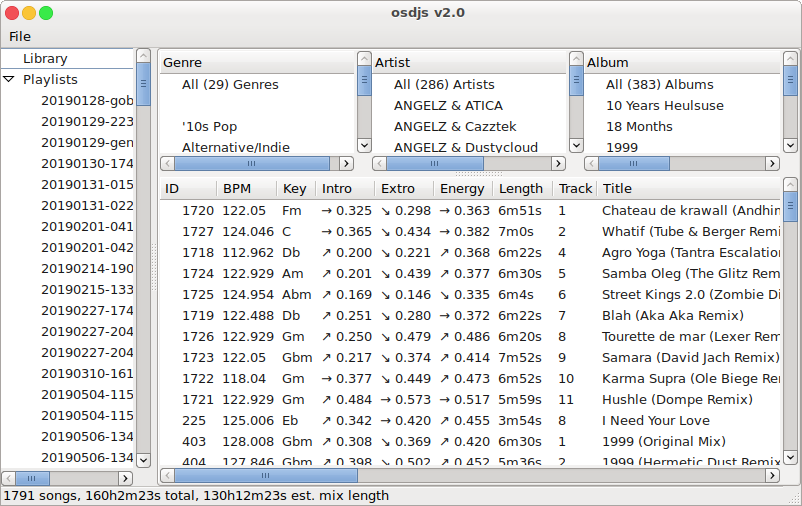
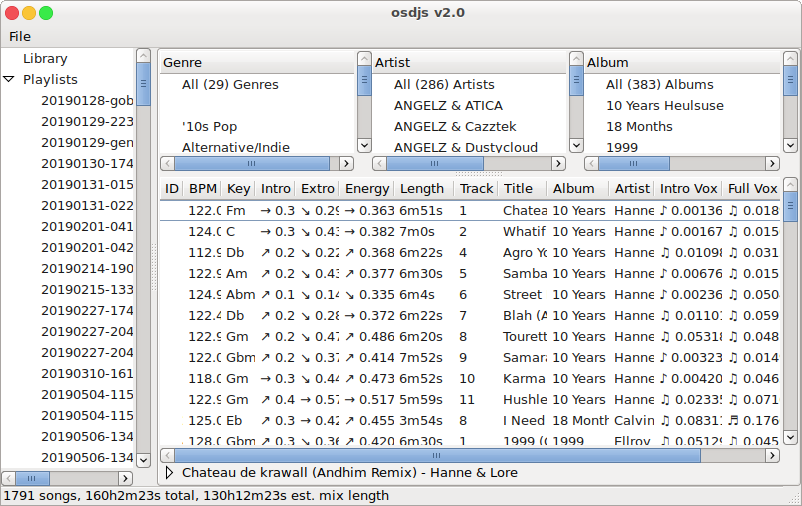
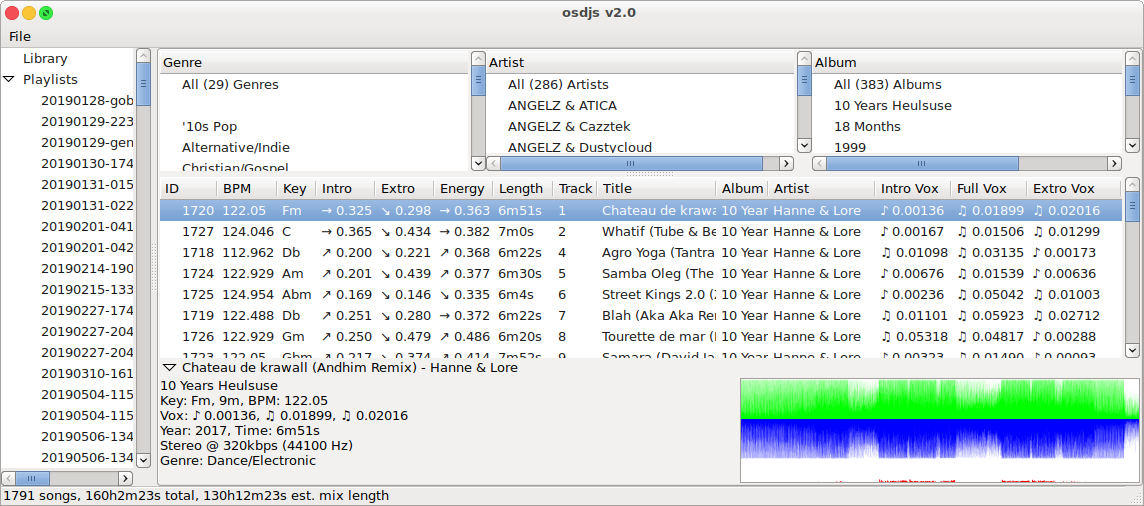
Okay, so what are we looking at in this last screenshot? This one basically demonstrates all the interesting base features. We've got a treeview on the left for managing the existing playlists, we've got the library filter selectors at the top of the content area, we've got the tracklist itself and then we've got the per-track-extra-details pane at the bottom.
Something neat to note is that statusbar at the bottom of the window frame...
1791 songs, 160h2m23s total, 130h12m23s est. mix length
This is a neat bit of guestimation based on an average 1-minute overlap between any two tracks and comprising of all the tracks visible in the main tracklist view. Not so useful on the main library but definitely useful on the playlist view (which we'll see in a moment).
Looking at the details view you can see a waveform representation of the track along with all the specific details for the selected track. This used to be a vital component of the process, but things, well, have evolved somewhat.
The titlebar lies
The version displayed is 2.0 however this is not actually true. This is actually the
third iteration of this codebase and if it had been a public project... lolz at all
the broken library databases that would be out in the wild right now haha
Okay so, we're starting to see two things, one is that there's all sorts of interesting
features and information presented for the DJ to work with, but, what made version 2.0
be worthy of declaring it in the titlebar?
Enter the playlist builder...
The File menu at the top left (the only standard application menu item), has two
items in it, "Quit" and "New Playlist". Given we can assume what the former does, let's
focus on the latter.
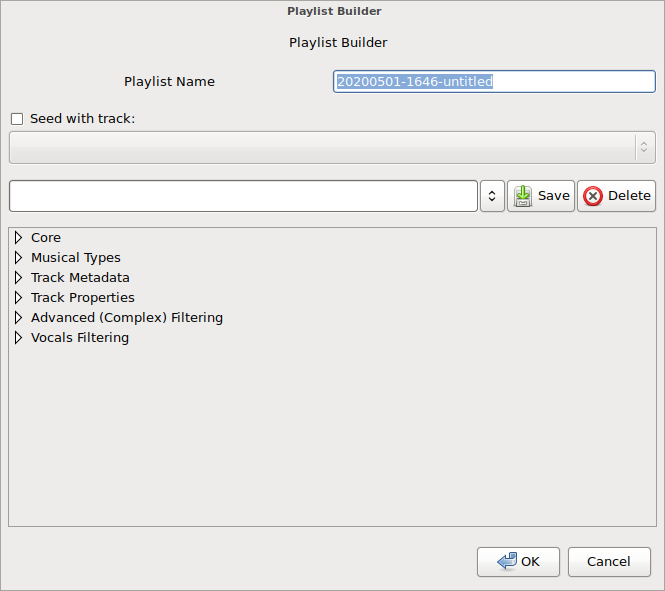
Okay, so there's a lot going on here, let's start at the top and work our way down.
Playlist Name
This is fairly obvious, it's the name for this new playlist we're about to build. By
default it populates the name with a datestamp (YYYYMMDD-HHMM) and the word "untitled"
which I would normally replace with the name of the first track in the setlist, for
example, one of my favorite and recent practice sessions was
20200423-0438-leavethisworldbehind.
Seed with track
The playlist builder can randomly select the first track or it can be specified by enabling the feature (click the checkbox) and selecting a track from the drop-down listing, or the more esthetically pleasing would be to select a track from the tracklist, right-click, then select "Seed new playlist" which will launch the builder dialog with the selected track configured as the seed.
Mysterious combobox-dropdown with "Save" and "Delete" buttons
This is a sort of preset management system. Configure the rest of the options in the pane below this section, give it a name in the text field and hit save. Next time you want those settings back, hit the dropdown and pick your preset by name.
The pane below... (pun intended)
In the above screenshot, the tree of configrable items is fully collapsed. There are a number of main branches or sections to these intricate settings. Let's explore them one at a time.
Core
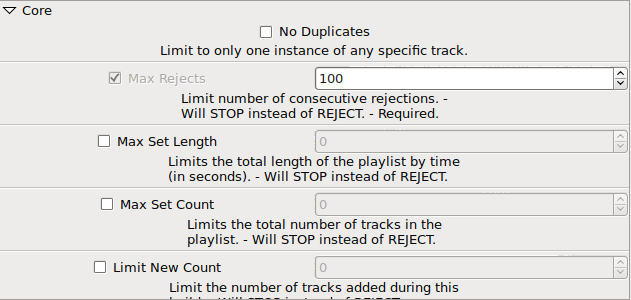
Most of the helpful tips should be self-explanatory. Max-rejects is one of the "must set" options and cannot be disabled, however, the default setting of 100 is quite harsh in practice.
Musical Types

Very simple features again.
Track Metadata
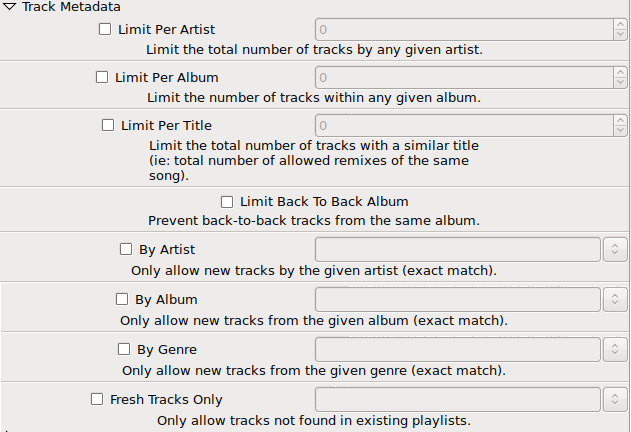
This time, we're starting to get a little deeper into the maze. That last option, "Fresh Tracks Only", that one is relatively new (last month or two I think) and it's basic purpose is to guarantee that I'm not committing some DJ faux pas with respect to track selection. For example, it's "proper" for DJ sets to conform to the following rules:
- do not play anything from the headlining DJ (if playing a venue)
-
do not play more than two tracks from the same album
- and if doing so, definitely do not play them back-to-back
-
do not play more than two tracks from the same artist
-
and if doing so:
- definitely do not play them back-to-back
- note that remixes of other tracks by the artist are more okay than using more than two tracks that are originals of the artist
-
and if doing so:
- use instrumental tracks in between vocal tracks
- use lower momentum tracks in between high energy tracks
There's probably a million other rules I'm neglecting because A) I've never been informed of all the novice errors I make and B) this is all that I could figure out based on listing to DJ sets my whole teenage + adult life.
Track Properties
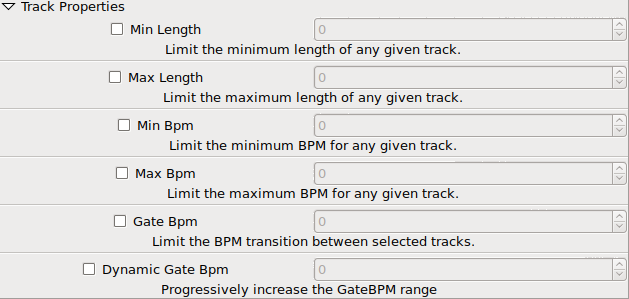
Again, nothing really ground breaking here... however... there is a nasty wart staring me right in the face though you most likely don't see it... "Dynamic Gate BPM". That setting is a complete hack of a feature to get around another problem I was facing. The way it works is like this, when the min/max BPM options are set, if your library of music isn't really congruent with your desired BPM range limit then you're going to get truncated setlists (they don't hit the max track count or the max time thresholds). So, instead of buying more music in the desire range, I hacked up this feature to dynamically increase the min/max BPM range after rejecting a track. The more tracks rejected by the builder process, the wider the BPM range becomes though it does get reset back to the "stock" limits when a track is selected instead of rejected.
I consider this technical debt because the feature itself manipulates the behavior of other features artificially (meaning without proper access controls and the other feature isn't even aware that it's being manipulated). This has caused so many bugs in BPM range limiting because I just wanted to jam the feature in so I could make a new mix 10 minutes later. Patience is a virtue and sometimes I have no patience with these personal projects of mine!
DO WHAT I MADE YOU TO DO YOU PILE OF BITS AND LET ME GET TO THE FUN STUFF!
Advanced (Complex) Filtering

Energy Slopes
Using bpm-tools to gather up the energy data, I again use math very poorly and
derive some nonsense numbers from raw data and attribute useful meaning. If you go
back to the screenshots showing the full tracklist view, you'll notice the little
unicode arrows in three of the columns: "Intro", "Extro" and "Full". These "slopes"
are the directional flow of the energy data. For example, the Intro is considered
to be the first minute of a track and so we take the first minute, divide it into
four parts, get the energy value of the first, is it greater-than-or-equal-to the
next part and then the third part and so on until one of three slopes is determined:
"upwards", "downwards" and "flat". Flat however is a bit of a misnomer because flat
really means "not up or down", which in practice means "be weary of flat slopes"
because "high", "low", "high", would fit the "flat" definition for example.
Low/High/Mean Deltas
These deltas are the thresholds for identifying the acceptable limits in comparing the energy slopes between two given tracks. These values are entirely technical debt and exposed to the (advanced) user because I HAVE NO IDEA WHAT THE MATH MEANS AND I HAVE NO IDEA WHAT GOOD VALUES WOULD BE FOR THESE THINGS LOL
So, I invented these magic numbers and formulas all over the place in this application and I have no idea if the values I've been selecting are any good other than the current preset configurations I use have been experimented with ad nauseam. They're "working" and doing what I need them to do, producing relatively good playlists that I can then prune through and work with.
Vocals Filtering
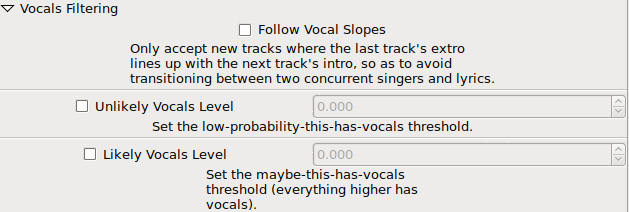
The descriptions in the screenshot here are more than adequate but let's learn a bit about what this really is and why spleeter is my saviour. If you haven't heard of it, here's their description:
Deezer source separation library including pretrained models.
Exactly what I needed. Something to split the sound layers from existing complete tracks. Essentially, during the import process, each track is split into two parts: "vocals" and "instruments". You can configure/use spleeter in many other ways too, for example: Automatically generate stems from ANY audio in Ableton + Max for Live! is a great video made by bcrypt. I love this sort of hackery. It's so much fun! Anyways, I'm digressing.
So, given these two tracks: vocals and instruments, I discard the instrument track completely and I only examine the vocal track. By reusing my bad math from the original Perl scripting, I'm simply adding up all the raw sample data and calculating averages. Then, based on profiling many tracks with and without vocals, identified some sane hard-coded thresholds and two configurable options which I've now settled upon with standard values. Again, these two options on the last screenshot, "Unlikely Vocals Level" and "Likely Vocals Level" are fully moldy warts that are developing some form of gangrene. Thank goodness you're only seeing the screenshots! LOL
A Bad Example of a Good Thing
And so I'd now like to conclude this first part of this two-part article. In this article, I've shown why this project is a Good Thing overall and in the next part I'll explore all the problems with the codebase, not just the "feature" problems but really take a dive into the many layers of technical debt.
Post-script
My apologies to the visually impaired for not properly captioning the actual text featured in the screenshots.
I hope you enjoyed this. Thanks for reading!